L'univers fascinant de l'apprentissage profond
2017-01-28 • VulgarisationIl y a trois semaines, j’ai commencé une maîtrise en apprentissage profond appliqué à la vision. J’ai commencé à m’intéresser au “deep learning” il y a quelques mois. Je trouve ce sujet fascinant! J’ai découvert une quantité de choses qui méritent d’être partagées. Voici donc la raison de la naissance de ce blog.
Comment un ordinateur peut-il apprendre ? En quoi l’apprentissage profond est-il profond ? Avant de pouvoir répondre à ces questions qui vous réveillent la nuit, il faut d’abord dévoiler quelques concepts importants : intelligence artificielle, apprentissage automatique, et réseaux de neurones artificiels.
L’intelligence artificielle
L’intelligence artificielle est une discipline scientifique recherchant des méthodes de résolution de problèmes à forte complexité logique ou algorithmique. (Wikipédia)
Ce domaine ne cherche pas à répliquer le fonctionnement d’un cerveau animal comme le nôtre. L’intelligence artificielle (IA) cherche à résoudre des problèmes qui nécessitent de l’intelligence. Par exemple : faire des calculs mathématiques ou jouer aux échecs. Pour ces deux exemples, il est possible de concevoir des “recettes” que l’ordinateur pourra exécuter, étape par étape.
La force de l’ordinateur est qu’il exécute des millions d’étapes par seconde sans se tromper, et ce sur une quantité énorme de données. Ainsi, “intelligence artificielle” n’est qu’un terme sensationnaliste pour décrire ce qui se passe dans une machine à calculer. Un aspect important de l’intelligence est l’apprentissage; or, les techniques d’IA n’utilisent pas toujours l’apprentissage! Cependant, certaines techniques le font.
L’apprentissage automatique
L’apprentissage automatique (Machine Learning, “ML”) est un champ d’étude de l’intelligence artificielle. Le Machine Learning permet de créer un système qui se forme une “compréhension” d’un problème en étant exposé à des exemples.
Un programme informatique typique est une “recette” spécifiée entièrement par le programmeur. Avec le ML, une partie importante du programme n’est pas donnée par le programmeur : elle est “apprise” automatiquement.
Voyons un usage du ML qui a beaucoup de succès : la reconnaissance d’images. Le défi ici est de faire un système qui reçoit une photo et retourne une description de ce qui se trouve dans cette photo. Une belle motivation à relever ce défi est de permettre aux malvoyants d’utiliser des applications comme Facebook, par exemple.
La classification
Typiquement, lorsqu’on parle de reconnaissance d’images, on parle de classification. D’abord, on fixe un certain nombre de classes, par exemple : chat, chien, auto, avion, camion, etc. Ensuite, on constitue une base de données d’exemples, où on associe des images avec leur classe respective. Enfin, on conçoit l’algorithme d’apprentissage qui va nous permettre d’obtenir une “compréhension intuitive” du problème.
 Le célèbre ensemble d’images CIFAR-10. Il contient 10 classes avec 6000 exemples chacune. CIFAR est l’acronyme de Canadian Institute For Advanced Research.
Le célèbre ensemble d’images CIFAR-10. Il contient 10 classes avec 6000 exemples chacune. CIFAR est l’acronyme de Canadian Institute For Advanced Research.
Grâce à cette “compréhension intuitive”, le classifieur retournera “chat” en voyant une photo de chat, ou “grenouille” en voyant une photo de grenouille. Si on ne lui a pas montré d’exemples de pommes, il sera inutile pour reconnaître cette classe. L’apprentissage se déroule comme suit :
- On initialise la “compréhension intuitive” (concrètement : un tas de nombres) avec du n’importe quoi. Le classifieur se trompera donc très souvent au départ.
- Le classifieur prend une image et tente de déterminer sa classe.
-
Le classifieur donne une probabilité \(p\) pour chaque classe. Éventuellement, s’il voit une photo de chat, il va donner quelque chose dans ce genre :
\(p_{chat} = \bold{60\%},\enspace p_{chien} = 35\%,\enspace p_{cheval} = 5\%\).
Cependant, au début de l’apprentissage, il risque de sortir quelque chose comme :
\(p_{chat} = \bold{3\%},\enspace p_{chien} = 2\%,\enspace p_{cheval} = 95\%\).
Bref, n’importe quoi !
- On calcule la perte, un nombre qui indique à quel point le classifieur se trompe. La magie des mathématiques nous permet d’obtenir la dérivée de la perte.
- Grâce à la dérivée de la perte, on sait exactement comment modifier la “compréhension intuitive” afin que le classifieur ait appris de son erreur.
- On retourne à l’étape 2 et on continue jusqu’à avoir vu tous les exemples (idéalement plusieurs fois).
Ouf! Toute une aventure! À ce moment, la “compréhension intuitive” accumulée permet au classifieur de deviner le contenu d’une image sans trop se tromper. Avant de continuer, récapitulons. Grâce à l’apprentissage automatique, on peut apprendre à un ordinateur comment deviner le contenu d’une photo. L’ordinateur ne suivra pas une liste d’étapes : il va utiliser une “compréhension intuitive” obtenue par un processus d’apprentissage.
Je vais conclure cette section avec une touche historique. Étonnamment, beaucoup de connaissances du ML existent depuis les années 80! C’est seulement récemment qu’on en récolte les fruits. Le succès de l’apprentissage automatique dépend principalement de deux choses:
- La quantité de données dont on dispose;
- La puissance de calcul dont on dispose.
À notre époque, ce ne sont pas ces ressources qui manquent.
Les réseaux de neurones
Les réseaux de neurones sont une des nombreuses techniques d’apprentissage automatique. Il s’agit de la technique qui a eu le plus de succès à ce jour. Je vais maintenant tenter de vulgariser cette technique.
Pas comme notre cerveau
Bien qu’un réseau de neurones artificiel soit inspiré en partie du cerveau animal, concrètement, il en est très loin! En général, ces réseaux sont une approximation trop grossière du fonctionnement du cerveau humain pour être utile aux neurosciences.
Les recherches en réseaux de neurones artificiels sont guidées principalement par les mathématiques et l’ingénierie, dans le but de créer des machines qui peuvent atteindre la généralisation statistique, en empruntant de temps à autre des intuitions aux sciences cognitives.1
La principale ressemblance entre notre cerveau et les réseaux de neurones artificiels est l’inter-connectivité des neurones. Notre cerveau contient cent milliards de neurones, chacune ayant en moyenne 7 000 connexions avec d’autres neurones.2
En comparaison, les réseaux de neurones appliqués aux problèmes de vision ont un nombre de neurones de l’ordre de dix, voire cent millions. Cependant, on peut attaquer bien des problèmes avec beaucoup moins de neurones.
 Des neurones biologiques — et sans gluten! Source : brainmaps.org
Des neurones biologiques — et sans gluten! Source : brainmaps.org
Des moyennes pondérées
Le fonctionnement d’un neurone artificiel est semblable à celui d’une moyenne pondérée. Dans l’illustration suivante, on voit la couche d’entrée (composée des pixels de l’image), et la couche de sortie (un score pour chaque classe). Remarquez qu’un pixel est connecté à chaque classe, et qu’une classe est connectée à chaque pixel.
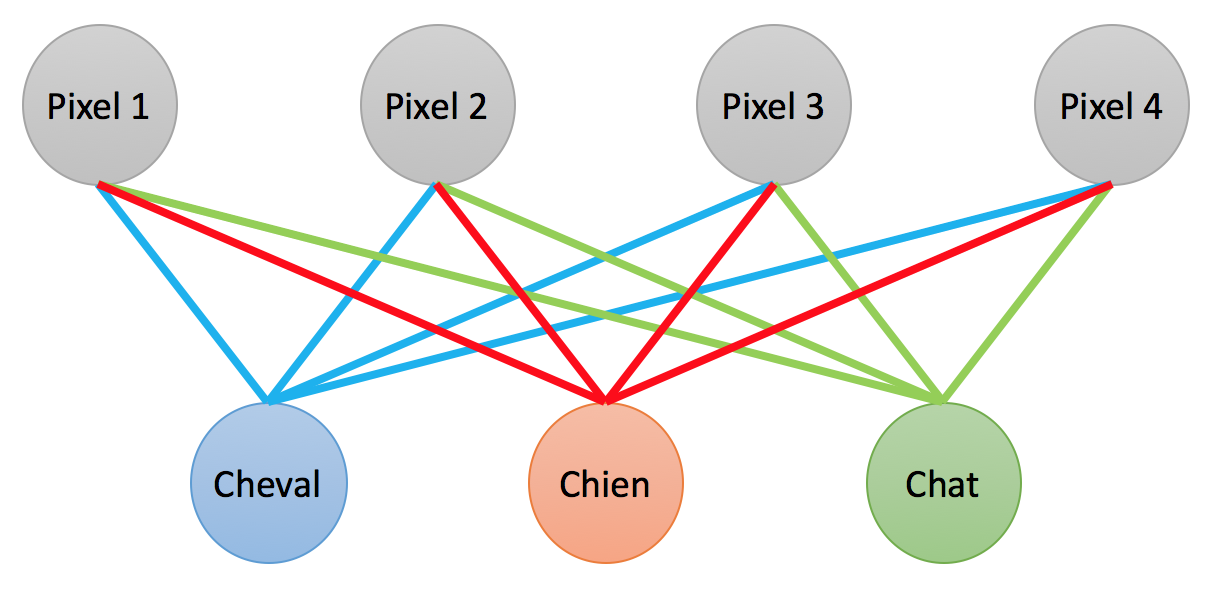 Chaque neurone “de sortie” fait une moyenne pondérée des neurones “d’entrée”. On utilise en réalité au moins 1024 pixels pour une image, et 3 neurones par pixel (un pour chaque composante RVB).
Chaque neurone “de sortie” fait une moyenne pondérée des neurones “d’entrée”. On utilise en réalité au moins 1024 pixels pour une image, et 3 neurones par pixel (un pour chaque composante RVB).
Chacune des connexions entre deux neurones a un poids, c’est-à-dire que le pixel 1 n’aura pas la même utilité que le pixel 2 pour déterminer si l’image contient un cheval. De même, le pixel 1 n’aura pas la même utilité pour déterminer si l’image contient un cheval que pour déterminer si elle contient un chien.
Le score associé à la classe “chat” sera donc :
\[s_{chat} = (x_1 \times w_1)+(x_2 \times w_2)+(x_3 \times w_3)+(x_4 \times w_4)\]où \(x_1\) est la valeur du pixel 1 et \(w_1\) est le poids du pixel 1 pour la classe “chat”. Cette opération est une moyenne pondérée (sans la division habituelle).3
Les poids de ces connexions sont en fait la fameuse “compréhension intuitive” dont je vous parlais à la section précédente ! Ce sont ces poids que l’on obtient par le processus d’apprentissage. Notez que la présence ou l’absence de connexion n’est pas quelque chose qui est appris. Dans le cas présent, on parle d’une connectivité dense entre les couches (il y a des connexions partout).
Il existe une multitude de façons de booster nos réseaux de neurones ! La méthode la plus importante est d’ajouter des couches de neurones entre la couche d’entrée et celle de sortie. On obtiendra alors un réseau de neurones profond.
Nous voici enfin arrivés à la section que vous attendiez tous !
L’apprentissage profond
Je peux maintenant vous dévoiler le sens du terme apprentissage profond! En fait, j’aime à penser qu’il s’agit d’une contraction de : apprentissage automatique par réseau de neurones profond.
Les couches de neurones qui se trouvent entre la couche d’entrée et celle de sortie s’appellent des couches cachées. À peu de choses près, les neurones cachés sont pareils aux neurones de sortie. Eux aussi, ils vont apprendre à reconnaître des classes. Cependant, ce seront des classes abstraites, comme par exemple : “oreilles pointues” ou “sabots”.4
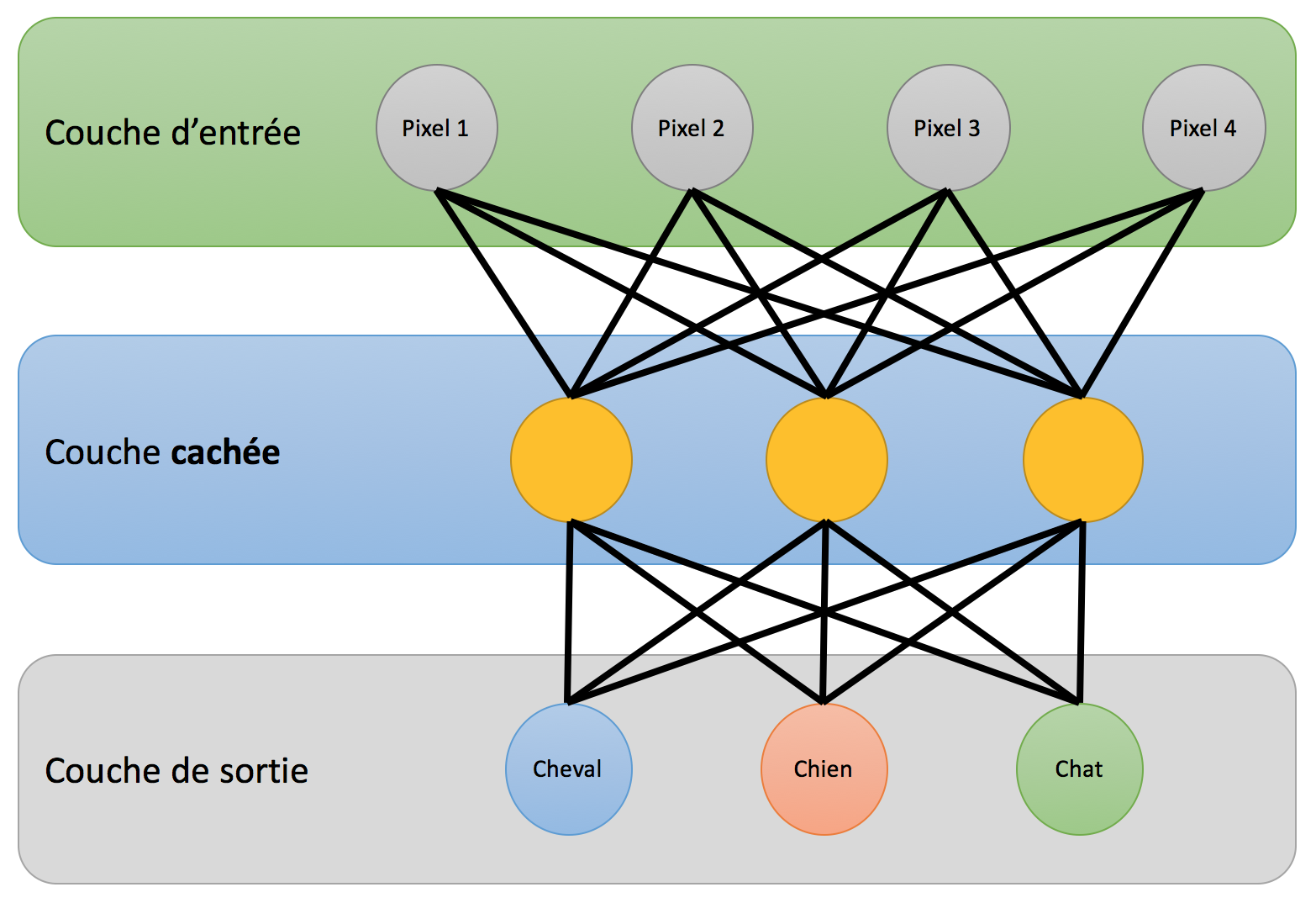 Réseau de neurones comprenant une couche cachée.
Réseau de neurones comprenant une couche cachée.
Les neurones de la couche suivante vont donc pouvoir bénéficier d’informations beaucoup plus utiles ! Par exemple, le neurone associé à la classe “chat” va donner un poids très élevé au neurone “oreilles pointues”. La couche de sortie pourra alors faire un bien meilleur travail que lorsqu’elle ne connaissait que la couleur des pixels dans l’image.
Comment choisit-on quelles caractéristiques vont être reconnues par la couche cachée ? Réponse : on ne le choisit pas. À vrai dire, on ne sait pas ce qui se passe dans cette couche, et on n’a pas besoin de le savoir. C’est le processus d’apprentissage qui va “faire ce choix”.
Bref, vous savez maintenant ce qu’est l’apprentissage profond. Mon approche a été d’introduire les concepts sur lesquels se base l’apprentissage profond afin de démystifier le terme. D’abord, nous avons vu que l’apprentissage automatique est une méthode d’intelligence artificielle qui “apprend par l’exemple”. Ensuite, nous avons vu que les réseaux de neurones profonds sont des réseaux de neurones qui comprennent des couches cachées.
J’espère que vous avez apprécié cette lecture ! Si vous avez des questions, des commentaires ou des suggestions, n’hésitez pas à me le dire par le biais de la section commentaires ci-bas.
À la prochaine !
Notes et références
-
Goodfellow, Bengio, Courville. Deep Learning, p.169. http://www.deeplearningbook.org “[…] modern neural network research is guided by many mathematical and engineering disciplines, and the goal of neural networks is not to perfectly model the brain. It is best to think of feedforward networks as function approximation machines that are designed to achieve statistical generalization, occasionally drawing some insights from what we know about the brain, rather than as models of brain function.” ↩
-
David A. Drachman. Do we have brain to spare? http://www.neurology.org/content/64/12/2004 ↩
-
En réalité, il s’agit d’une somme pondérée. J’utilise le terme moyenne pondérée car j’ai l’impression qu’il est mieux connu en dehors des milieux mathématiques. Cette opération est aussi le produit scalaire entre le vecteur des pixels et le vecteur des poids. ↩
-
J’ai pris un raccourci pour simplifier l’explication. En réalité, pour détecter des caractéristiques visuelles du genre “oreille” ou “sabot”, qui peuvent se trouver à n’importe quel endroit dans l’image, il faut utiliser un réseau de neurones à convolution. J’en parlerai dans un prochain article. ↩